Figure fig:totals
Category sizes, by Count for bigrams.

We've so far studied just word meanings. We have tried to embrace the fact that word senses are constantly being pushed around by the morphosyntactic and discourse context in which they occur, but we were still, in the end, just creating lexicons. A viable theory of meaning has to come to grips with semantic composition — how word meanings combine to form more complex meanings. The goal of this lecture is to take some tentative steps in that direction. This should also provide some connections with Noah Goodman's course and Shalom Lappin's lecture today (this place, next period!).
If you haven't already, get set up with the course data and code.
Semantic composition is an extremely active area of research in natural language processing; having gotten good at building rich lexicons, the NLPers have now turned their attention to the core problem of formal semantics, and they are making rapid progress, with new papers appearing all the time. Here's a partial list of people who are pursuing this issue, from a variety of perspectives (please let me know whom I've forgotten!):
In addition, a number of computational workshops and conferences have come together this year to form *Sem, which will probably evolve into a primary outlet for work on this topic.
It's too much to tackle the full problem of compositionality. Thus, I'm going to focus on a particular kind of compositional interaction, namely, those involving adverb–adjective combinations. In our ratings data, we were starting to see that modifiers have complex but systematic effects on the sentiment profiles of adjectives, so this seems like a natural place to start. It's also a vital part of good sentiment analysis, since one's text-level predictions about sentiment can be greatly improved simply by being sensitive to negation, attenuation, and emphasis as they relate to sentiment adjectives.
Here is my framing of the problem: suppose we have a bigram w1 w2 (like absolutely amazing) that has vector representation V. Suppose also that we also have separate vector representations for w1 and w2, call them v1 and v2. How can we use v1 and v2 to construct V? This is just the question of semantic compositionality (how does the meaning of the parts determine the meaning of the whole?), but phrased in terms of vector-space representations of meaning.
My experiments are directly inspired by those in this new paper by Richard Socher (who pursues more ambitious models than we will).
In principle, we can go after this question using any vector representation. In the last class, our vectors were derived from co-occurrence patterns. In the classes before that, our vectors were probability values, one for each category (star rating or EP reaction distribution). Here, we'll use just the star-rating vectors obtained from IMDB data, because it's possible to grasp intuitively what those vectors are like, whereas the 1000-plus dimensions of the unsupervised approaches are mind-boggling.
The data file for this unit:
The column values:
This is a big file:
As before I've written some code to facilitate interacting with the data:
The basic structure of the code is similar to previous lectures: functions for extracting subframes of the data and functions for visualizing the results. What's really new is the set of functions for making predictions about compositionality.
The subframe extraction function is bigramCollapsedFrame. It allows you to extract bigrams, or even unigrams, based on their column values. Its only required argument is a data.frame like bi above, though calling it with only this argument might cause some kind of explosition (not literally), since it will try to collapse the entire file.
Here's an example involving a fully specified bigram:
The Category values are centered at 0 to create a more intuitive scale, with negativity corresponding to negative numbers, as in our first lecture.
You can leave off one or both of the tag arguments:
You can even leave off one or both of the word arguments:
You can look at a specific value for just Word1 or Word2, with or without their tag specifications:
A word of caution: it often matters whether you use word1 or word2 to specify the word you want to look at (and similarly for tag1 and tag2. This is because we are looking at a selected subset of the bigrams data, and thus the unigram distributions derived from the two slots can differ.
The function bigramPlot is just like our other plotting functions for supervised data. Here is a call with all of the default arguments given as their defaults, except word1, which I specified:

The word and tag arguments behave like the corresponding arguments for bigramCollapsedFrame.
You can use ylim to adjust the y-axis, which is important if you need a uniform y-axis in order to do comparisons.
The col argument gives the color of the plot lines. 1 is the same as "black". (Colors can be specified with integers or with strings like "black", "blue", and so forth.)
You can mostly ignored the add argument. If set to TRUE, it will try to add your plot line to an existing plot. This is used by the function bigramCompositionPlot, which is described in the next section.
Exercise ex:plot Play around with bigramPlot. In anticipation of the work we want to do with this data, you might focus on some particular interactions — for example, can you start to discern how a given modifier interacts with the things it modifies?
The function bigramCompositionPlot allows you to compare a bigram with its constituent parts. Here is a typical call:

You can optionally specify tag1 and tag2 to further restrict your gaze. ylim allows you to specify the y-axis values.
To add expected category values, use ec=TRUE.
Exercise ex:plot Continue the investigations you began above, now using bigramCompositionPlot to get an even sharper perspective on what modifiers do to their arguments. At this point, you might pick a single modifier and sample argument (word2) values to see whether patterns emerge. The ec=TRUE flag might start to suggest a coarse-grained semantics.
Semantic theory strongly suggests that, in adverb–adjective constructions, the adverb will take the adjective as its argument and do something with it to create a new adjectival meaning. In present terms, this comes down to see how adverbs modulate the distributional profiles of the things they modify.
One simple high-level method for doing this is to look exhautively at all of the modification data we have for a particular pattern. Expected Category (EC) values provide a rough first summary: we might expect some adverbs to push these values out towards the edges, with others pushing them to the middle.
Thus, for any adverb Adv and adjective Adj, we can look at the different between the EC for Adv and the EC for Adj. Perhaps Adv is a function that does something systematic to EC values.
Compiling all of these differences takes a lot of computing time and some extra trickery with R tables. Thus, I've pre-compiled it into a CSV file — just for the adverbs and adjectives, because my laptop was struggling under the weight of the full vocabulary for the bigrams data:
As you can see, this contains the distributions for both the bigram and for Word2. We will use these later. For now, we can focus on the columns relevant for ECs:
The function ecAdjustmentPlot plots, for any given adverb (value of Word1), the distribution of ArgumentEC - BigramEC.

Exercise ex:ecadj Continue your adverbial investigations (begun in exercise ex:plot and exercise ex:ec), but now using ecAdjustmentPlot. Try to use the distributions you see to formulate generalizations about how specific classes of adverbs work.
As before, EC values are useful but too limited (and sometimes too untrustworthy) to carry the day. Since they are point estimates, they ignore a lot of the information we have in the sentiment distributions.
What we a really want is to define adverbs as functions that take in adjectival sentiment distributions and morph them somehow. A good theory will be one that morphs them into something resembling the distributions we observe for the corresponding bigram. In the terms of these sentiment distributions, that just is semantic composition.
The language of probability suggests two simple hypotheses right off the bat:
I've called this section "Symmetric compositional hypotheses" because both of these analyses assume that the adverb and the adjective are equal partners, with neither truly a functor on the other.
Both of these analyses will seem wrong to the semanticist in you, but, bear with me! It is still instructive to see how well they work.
Returning to bigramCompositionPlot, we can plot these predictions alongside the empirical estimates by filling in values for the optional prediction.func argument. The function Intersective models the multiplicative hypothesis, and the function Disjunctive implements the additive hypotheses:


Exercise ex:sym Explores these compositional hypotheses. What kinds of values do they tend to give? Are there are adverbs for which their assumptions seem approximately true or very clearly false. Why?
Our guiding insight from compositional analyses is that the adverb will be a functor on the adjective, taking in its meaning and transforming it in some way to produce a meaning for the whole. The above simple analyses don't make good on this.
As a first pass, suppose you want to analyze a particular adverb Adv. Consider all of the adverb–adjective bigrams it participates in. In each case, it warps the adjective to create a new vector. That is, in each case, for each star rating, it performs an adjustment, moving the probability up or down:

Hypothesis: an adverb is a function that takes an adjective meaning (qua probability vector) V and adjusts each Vi by the mean difference it imposes for category i, with the mean take over all the adjectives in our data.
The mean differences are the maximum likelihood estimates, so this is a natural hypothesis to start with, assuming that the data are underlyingly linear in a way that makes differences appropriate.
The file that we loaded above as aa
contains the values we need to calculate the mean difference vector for each adverb. Here is a example of how to do that:
The adjustments are then made by adding the means from the probabilty values for the adjective, and then renormalizing to get back into probability space.
To see these predictions in plots, we can again use bigramCompositionPlot, here with prediction.func given by Differences. You also need to use the keyword argument prediction.func.arg=a so that Differences gets that table of values as one of its arguments.
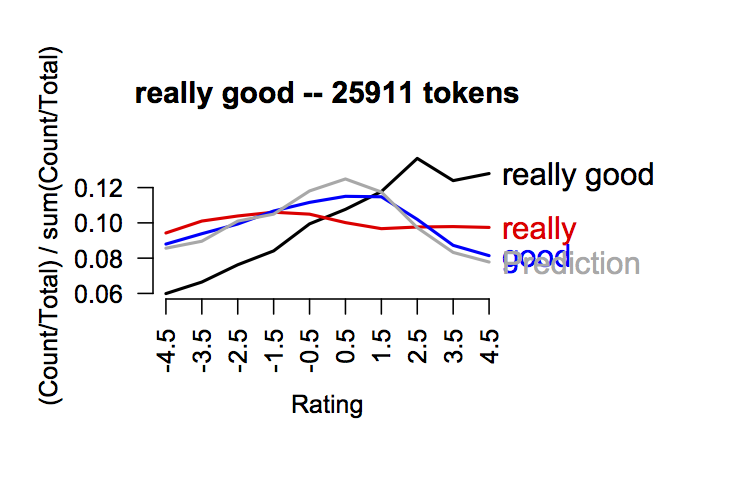
Exercise ex:additive Use bigramCompositionPlot to try to home in on the strengths and weaknesses of this additive hypothesis about how modifiers work. Are there inherent limitations to this approach that we should be aware of?
To assess the above functions, I calculated all the predictions for the bigrams in our aa data.frame and used the KL-divergence as a measure of how close we had come to reconstructing the observed bigram distribution. Here are the (surprising) results; lower (smaller divergence from truth) is better. The symmetric intersective analysis is in the lead!



Exercise ex:mult Another natural asymmetic analysis is a multiplicative version of the additive one above. Here, we would multiply the bigram and adjective probabilities to get a vector of adjustments X and then use a ratio X/A, where A is the vector of adjective probabilities, to make adjustments during composition. Implement this using FunctorStyleModel in composition.R, on the model of Differences, and see how it does.
Home
 This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.